Overview
Ever since being introduced to the TeX ecosystem during my time as an undergrad at UCI, I have enjoyed exploring typesetting and learning what makes TeX tick in a different way than other text rendering engines. It is also interesting learning about portable ways to share documents, and what sort of interesting dependencies there are between the format and the underlying system which tries to display that format.
As a brief aside, Douglas Hofstadter touches on this quite a bit in his various books, the dependence of meaning or interpretation on the lower level “interpreter” or background. I have attempted to find some of the vivid examples that he brings up (for example, the information in DNA requiring a particular chemical environment in which to be interpreted to make proteins; or another analogy with a phonograph), but have been unable to so far. Looking for the terms substrate, environment, chemistry, and DNA in the indices of both I am a Strange Loop and Metamagical Thema have all failed to yield the section I was looking for. I will have to come back and look again soon. The closest I have found is in his article title Waking Up from the Boolean Dream, or, Subcognition as Computation in the section The Substrate of Active Symbols Does Not Symbolize, for my own future reference.
In any case, this idea that different “environments” and the primitives that it exposes leads to more easily- and more difficultly-expressed ideas is an interesting one, and it relates to TeX in the way that there is much more control over fine-grained typographic decisions in TeX than say, HTML.
As another aside, one project I have been curious to attempt is that of hacking some renderer—say Chromium’s Blink—to shunt out each text-justify: inter-word|inter-character-styled paragraph’s rendering out to something like TeX in order to try and get some very nice (though slower) justification unlike that which is offered out of the box. Surely it can be done, and I’ve been eager to tear apart XeTeX’s or other TeXs’ source to figure out how to easily do it.
All that to say, I like TeX a bit more because it yields results that sometimes look much prettier. But, I would still like an HTML resume for easier viewing and sending to people. Thus, the genesis of this project.
The main goal is to have a simple database backend for the resume and render it either to PDF through TeX or to HTML whenver I like.
The original SQLite, jq, mustache, and bash implementation
While I had a version of my resume in TeX format, I decided I wanted to have access to the same information regardless of whether I was rendering using TeX or some other format. In order to do this I decided to cubbyhole all the data in a teensy SQLite database that I could modify, query, and tweak to my heart’s delight.
An added benefit of rendering from the database is the opportunity to create many different resumes for different potential positions, with different responsibilities and details highlighted for each role.
In order to achieve this goal, I start with the following schema.
CREATE TABLE work_role (
id INTEGER PRIMARY KEY,
company TEXT,
location TEXT,
role TEXT,
start_date INTEGER,
end_date INTEGER,
link TEXT,
expanded_company TEXT,
enabled INTEGER);
CREATE TABLE research_role (
id INTEGER PRIMARY KEY,
institution TEXT,
project TEXT,
role TEXT,
start_date INTEGER,
end_date INTEGER,
advisor TEXT,
topics TEXT,
link TEXT,
expanded_institution TEXT,
enabled INTEGER);
CREATE TABLE responsibility (
id INTEGER PRIMARY KEY,
role INTEGER,
brief TEXT, enabled_x TEXT, enabled INTEGER,
FOREIGN KEY(role) REFERENCES roles(id));
CREATE TABLE detail (
id INTEGER PRIMARY KEY,
parent INTEGER,
enabled INTEGER,
text TEXT,
FOREIGN KEY(parent) REFERENCES detail_parent(id));
CREATE TABLE detail_parent (
id INTEGER PRIMARY KEY,
work_role_responsibility INTEGER,
research_role_responsibility INTEGER,
FOREIGN KEY(work_role_responsibility) REFERENCES work_role(id),
FOREIGN KEY(research_role_responsibility) REFERENCES research_role(id));SQLite has a JSON extension which helps out very much in create JSON objects from rows. I’ve learned that it is best to leave a database system to do the things it’s very good at—for example relational algebra for complex queries, aggregating, and whatnot. Here is an example query for each of the work roles, with a similar query being performed for each of the research roles.
SELECT
json_object(
'company', `work_role.company`,
'expanded-company', `work_role.expanded_company`,
'role', `work_role.role`,
'enabled', `work_role.enabled`,
'start-date', `work_role.start_date`,
'end-date', `work_role.end_date`,
'responsibilities', json_group_array(json_extract(responsibilities, '$'))
)
FROM
(
SELECT
json_object(
'brief', responsibility.brief,
'enabled', responsibility.enabled,
'details', json_group_array(
json_object(
'enabled', detail.enabled,
'detail', detail.text)))
AS responsibilities,
work_role.id AS 'work_role.id',
work_role.company AS 'work_role.company',
work_role.expanded_company AS 'work_role.expanded_company',
work_role.location AS 'work_role.location',
work_role.role AS 'work_role.role',
work_role.start_date AS 'work_role.start_date',
work_role.end_date AS 'work_role.end_date',
work_role.link AS 'work_role.link',
work_role.enabled AS 'work_role.enabled'
FROM work_role
INNER JOIN responsibility
ON responsibility.role = work_role.id
AND responsibility.enabled = 1
INNER JOIN detail_parent ON work_role_responsibility = responsibility.id
INNER JOIN detail
ON detail.parent = detail_parent.id
AND detail.enabled = 1
WHERE work_role.enabled = 1
GROUP BY responsibility.id
ORDER BY work_role.start_date DESC
)
GROUP BY `work_role.id`
ORDER BY `work_role.start_date` DESCThe above query then results in the following JSON
{
"company": "Panasonic Avionics Corporation",
"expanded-company": null,
"role": "Development and Operations Engineer",
"enabled": 1,
"start-date": 1578009600,
"end-date": 0,
"responsibilities": [
{
"brief": "General",
"enabled": 1,
"details": [
{
"enabled": 1,
"detail": "Used Japanese in a business context to bring local and Japan-based teams closer together on development and operations initiatives"
}
]
},
{
"brief": "Site reliability engineering",
"enabled": 1,
"details": [
{
"enabled": 1,
"detail": "Designed, built, and maintained highly-available Elasticsearch and Logstash clusters in order to reduce costs associated with Splunk logging infrastructure ingesting half a terabyte each day"
},
{
"enabled": 1,
"detail": "Built and maintained many Kubernetes clusters for different departments in the organization using Terraform, Rancher Kubernetes Engine (\\texttt{rke}), and Rancher"
},
{
"enabled": 1,
"detail": "Evaluated many underlying operating systems (including CentOS, Fedora CoreOS, Rancher OS), container runtimes, and operational tools for Kubernetes clusters"
}
]
},
{
"brief": "Development and operations",
"enabled": 1,
"details": [
{
"enabled": 1,
"detail": "Participated in cross-functional design between Software Engineering and Information Technology departments designing build pipelines for aircraft firmware libraries and executables"
},
{
"enabled": 1,
"detail": "Contributed scripts and documentation to open source containerization projects such as Bitnami's \\texttt{etcd} distribution and Rancher user interface"
},
{
"enabled": 1,
"detail": "Spearheaded change to vSphere's CSI storage driver for resizable persistent storage for container workloads"
},
{
"enabled": 1,
"detail": "Managed organization-wide virtual machine state using CFEngine (an alternative to SaltStack, Ansible,"
},
{
"enabled": 1,
"detail": "Built custom virtual machine images integrated with organization-specific configurations of NTP, DNS, Active Directory, NFS, \\textit{et cetera}"
},
{
"enabled": 1,
"detail": "Evaluated use of vSphere 7's vSphere with Kubernetes product with Tanzu, vSphere Cloud Native Storage as an alternative to Terraform, \\texttt{rke}, Rancher stack"
}
]
}
]
}
{
"company": "ICANN",
"expanded-company": "Internet Corporation for Assigned Names and Numbers",
"role": "Systems Engineer",
"enabled": 1,
"start-date": 1542240000,
"end-date": 1577923200,
"responsibilities": [
{
"brief": "Full-stack web development",
"enabled": 1,
"details": [
{
"enabled": 1,
"detail": "Apache \\texttt{ProxyPass} and FastCGI to backends, load balancing, Spring framework"
},
{
"enabled": 1,
"detail": "Lent efforts to Drupal/Rails developers in debugging issues, often stemming from an unsteady base in *nix philosophy"
}
]
},
{
"brief": "Site reliability engineering",
"enabled": 1,
"details": [
{
"enabled": 1,
"detail": "Maintained logging and alerting infrastructure in a stack using Splunk, Zabbix, and OpsGenie"
},
{
"enabled": 1,
"detail": "Maintenanced multi-master MariaDB clusters and Galera MariaDB clusters"
}
]
},
{
"brief": "Development and operations",
"enabled": 1,
"details": [
{
"enabled": 1,
"detail": "Maintained three separate Kubernetes clusters with combined totals of 544 CPUs, 3.5 TiB of memory, and north of 1200 pods"
},
{
"enabled": 1,
"detail": "Developed virtual machine templates using \\texttt{qemu}, VSphere SDK"
},
{
"enabled": 1,
"detail": "ElasticSearch, MySQL multi-master replication, etcd, Alfresco, DotCMS, Galera, Kafka, Spinnaker, Jenkins, Kubernetes, Helm charts, AWS, ThreadFix, NetSparker, BurpSuite, SonarQube, ESXI, VSphere, Site24x7"
},
{
"enabled": 1,
"detail": "Built tools for enforcing nomenclature in various platforms to line up with our configuration management database"
},
{
"enabled": 1,
"detail": "Automated various F5 load balancer tasks via the the F5 Python SDK"
}
]
}
]
}
{
"company": "McKinley Equipment Corporation",
"expanded-company": null,
"role": "Internet of Things Engineer",
"enabled": 1,
"start-date": 1468540800,
"end-date": 1534291200,
"responsibilities": [
{
"brief": "Embedded firmware development",
"enabled": 1,
"details": [
{
"enabled": 1,
"detail": "Designed and implemented accelerometer applications for custom PCB to detect industrial dock leveler event detection"
},
{
"enabled": 1,
"detail": "Communicated with custom PCB peripherials over SPI, I2C, RS232, and RS485 using custom protocols"
},
{
"enabled": 1,
"detail": "Designed and implemented communication protocol with other processors on RS485 bus "
},
{
"enabled": 1,
"detail": "Interfaced with \\texttt{mbed} library to facilitate communication between host processor and MultiTech mDot LoRa module"
}
]
},
{
"brief": "Development and operations",
"enabled": 1,
"details": [
{
"enabled": 1,
"detail": "Developed build strategy for above firmware using CMake"
},
{
"enabled": 1,
"detail": "Automated builds, designed release strategy using BitBucket Pipelines and Docker"
},
{
"enabled": 1,
"detail": "Developed and maintained SaltStack recipes for configuration and management of remote IoT devices "
},
{
"enabled": 1,
"detail": "Developed dev. op.'s strategy to manage remote IoT devices using SaltStack"
},
{
"enabled": 1,
"detail": "Utilized \\texttt{gdb} Python bindings for automated C++ source code generation"
},
{
"enabled": 1,
"detail": "Wrote documentation using BitBucket's Confluence along with a home\\hyp{}grown tool inspired by Scheme's \\textit{Scribble} and Emacs's \\texttt{org-mode}"
}
]
},
{
"brief": "C++ and Python software development in a Linux environment",
"enabled": 1,
"details": [
{
"enabled": 1,
"detail": "Wrote message queuing applications for transporting device data from edge devices to servers using MQTT, SQLite and HTTP REST APIs"
},
{
"enabled": 1,
"detail": "Automated correlation of embedded accelerometer data with video footage using Python and FFMpeg "
},
{
"enabled": 1,
"detail": "Compiled custom Linux kernels for the Intel Edison, MultiTech Conduit, and the Samsung Artik "
},
{
"enabled": 1,
"detail": "Designed tools for real-time profiling of relevant IoT-enabled industrial equipment with non-developer ease of use as a design goal % Maybe we can talk about using ffmpeg here to animate different % thresholds for the accelerometer data"
}
]
}
]
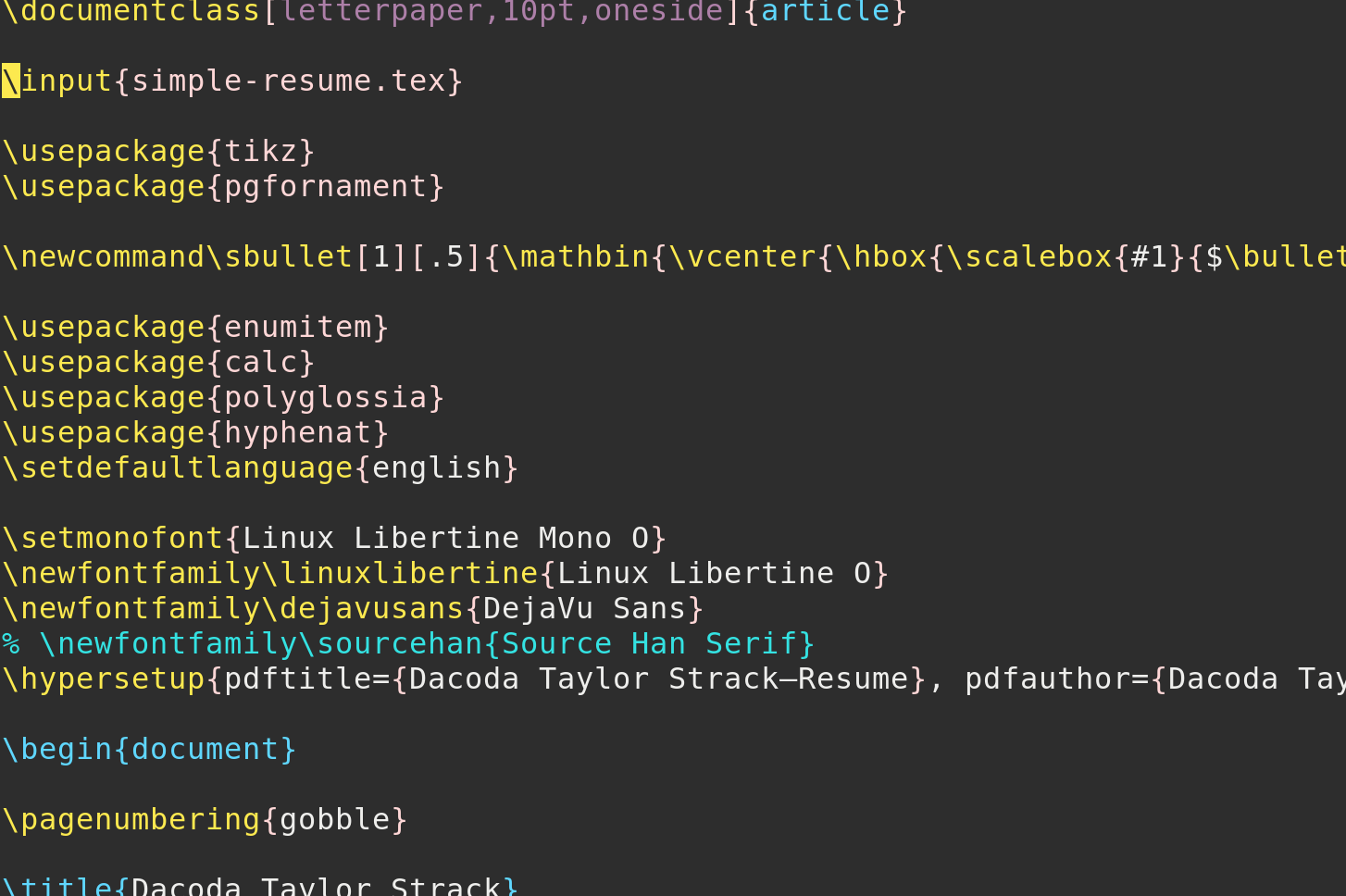
}The above JSON is then rendered into the following mustache-templated TeX
\documentclass[letterpaper,10pt,oneside]{article}
\input{simple-resume.tex}
\usepackage{tikz}
\usepackage{pgfornament}
\newcommand\sbullet[1][.5]{\mathbin{\vcenter{\hbox{\scalebox{#1}{$\bullet$}}}}}
\usepackage{enumitem}
\usepackage{calc}
\usepackage{polyglossia}
\usepackage{hyphenat}
\setdefaultlanguage{english}
\setmonofont{Linux Libertine Mono O}
\newfontfamily\linuxlibertine{Linux Libertine O}
\newfontfamily\dejavusans{DejaVu Sans}
% \newfontfamily\sourcehan{Source Han Serif}
\hypersetup{pdftitle={Dacoda Taylor Strack―Resume}, pdfauthor={Dacoda Taylor Strack}, pdfcreator={XeLaTeX}, hidelinks}
\begin{document}
\pagenumbering{gobble}
\title{Dacoda Taylor Strack}
\begin{subtitle}
\href{https://www.google.com/maps/place/3033+Coolidge+Ave+\%2359B,+Costa+Mesa,+CA+92626/@33.6817089,-117.9062447,17z/data=!3m1!4b1!4m5!3m4!1s0x80dcdf40ff48ef71:0xa15608972374ea2!8m2!3d33.6817089!4d-117.904056}
{3033 Coolidge Avenue 59B, Costa Mesa, California, 92626, USA}
\par \href{mailto:dacoda.strack@gmail.com} {dacoda.strack@gmail.com}
\,\BulletSymbol\, +1\,(858)\,344-9014 \,\BulletSymbol\,
\href{https://dacodastrack.com} {https://dacodastrack.com}
\end{subtitle}
\vspace*{-2.5ex}
\begin{body}
\section{Work Experience}
{{=<% %>=}}
<%#companies%>
\href{<%& link %>} {\textbf{<%& company %>}} <%& location %>\dotfill <% start-date %> -- <% end-date %>
\par {\small \it <%& expanded-company %>}
\par <% role %>
\begin{detail}
\vspace{0.4ex}
\setitemize{nolistsep,itemsep=0.25ex}
% \setitemize[2]{label={\char"25CF}}
\setitemize[2]{label={$\sbullet[.6]$}}
\begin{itemize}[leftmargin=1em, itemsep=0.6ex, topsep=0.5ex]
<%#responsibilities%>
\item[] \textbf{<%& brief %>} %
\begin{itemize}
<%#details%>
\item <%& detail %>
<%/details%>
\end{itemize}
<%/responsibilities%>
\end{itemize}
\end{detail}
\EntryGap
<%/companies%>
\vspace*{0.75ex}
\fancyrule
\section{Research Experience}
<%#research%>
\href{<%& link %>} {\textbf{<%& institution %>}} \dotfill <%& start-date %> -- <%& end-date %>
\par {\small \it <%& expanded-institution %>}
\par <%& role %>
\begin{detail}
% \vspace*{-1ex}
% \begin{center}
% \hspace*{-5em}
% \begin{tabular}{@{}r@{\ \,}l}
% \textit{Project} & <% project %> \\
% \textit{Supervisors} & <% advisor %> \\
% \textit{Research areas} & <% topics %> \\
% \end{tabular}
% \end{center}
% \begin{itemize}[nolistsep,topsep=1ex,bottomsep=0pt]
\begin{itemize}[nolistsep]
<%#details%>
\item <%&detail%>
<%/details%>
\end{itemize}
\end{detail}
<%/research%>
\vspace*{1ex}
\fancyrule
\section{Education}
\textbf{Bachelor of Science in Electrical Engineering}
\par University of California, Irvine
\end{body}
\end{document}Most of the above boils down to a lot of work templating things out, but the script that ties it altogether is rather simple.
#!/bin/bash
sqlite3 db/db.sqlite3 \
< src/sql/work-roles-json.sql \
| jq -Lsrc/resume 'include "resume" ; workRoles' \
| jq -s '{"companies": .}' \
> build/work-roles.json
sqlite3 db/db.sqlite3 \
< src/sql/research-roles-json.sql \
| jq -Lsrc/resume 'include "resume" ; researchRoles' \
| jq -s '{"research": .}' \
> build/research-roles.json
jq -s '.[0] * .[1]' \
build/research-roles.json \
build/work-roles.json \
> build/together.json
mustache build/together.json src/tex/skeleton.tex \
> build/resume.tex
( cd build ; xelatex resume.tex )The result is shown in the PDF resume here.
The HTML version
So the above paradigm works well, but relies on some programs not typically available in a web browser. Of course, another mustache template could be made for an HTML page, but building an HTML resume makes you think about having an interactive resume editor and perhaps being able to share this project more broadly with the world. For that reason, I set out
Foray into Webassembly with jq
My first thought was to compile jq to WASM so that I could use the same jq scripts I had for the desktop version. After taking a look at some repositories that have compiled jq for the browser previously, I found the project unworkable. Regardless, it served to lead to on the right track to properly compile jq with emscripten.
emconfigure ./configure --with-oniguruma=builtin --disable-maintainer-mode
emmake make LDFLAGS=-all-static -j8
/bin/sh ./libtool --silent --tag=CC --mode=link /home/dacoda/projects/emsdk/upstream/emscripten/emcc \
-Wextra -Wall -Wno-missing-field-initializers -Wno-unused-parameter -Wno-unused-function \
-I./modules/oniguruma/src \
-g -O1 \
-static-libtool-libs -all-static \
-s INVOKE_RUN=0 \
-s EXPORT_ALL=1 \
-s EXIT_RUNTIME=0 \
-s ASSERTIONS=1 -s SAFE_HEAP=1 -s STACK_OVERFLOW_CHECK=1 \
--pre-js test-pre.js \
--post-js test-post.js \
-o jq.js src/main.o libjq.la -lmAfter running the above in the root of the jq repository, out pops some WASM and a Javascript file for loading and interacting with that WASM. Now, let’s figure out how to get SQLite running.
Standing on the shoulders of giants with sql.js
Thankfully, lots of people have wanted to use SQLite in the browser, there are already many solutions to this problem. I chose to use this sql.js repository which has some nice demonstrations of running queries in the browser on the client side. The only small tweak we are going to make to this repository is adding a define flag to enable JSON (-DSQLITE_ENABLE_JSON1).
After recompiling the WASM with support for JSON, we will appropriating the interactive query executor in examples/GUI/ for our own purpose of rendering the resume. The only small downside here is the reduplication of work that was previously done in jq with Javascript.
1d0
< var execBtn = document.getElementById("execute");
4,6d2
< var commandsElm = document.getElementById('commands');
< var dbFileElm = document.getElementById('dbfile');
< var savedbElm = document.getElementById('savedb');
8,18d3
< // Start the worker in which sql.js will run
< var worker = new Worker("../../dist/worker.sql-wasm.js");
< worker.onerror = error;
<
< // Open a database
< worker.postMessage({ action: 'open' });
<
< // Connect to the HTML element we 'print' to
< function print(text) {
< outputElm.innerHTML = text.replace(/\n/g, '<br>');
< }
28a14,84
> function fixupDate(date) {
> if ( date == 0 )
> return 'Present';
>
> var newDate = new Date(1000 * date)
> return newDate.toLocaleDateString(undefined, {month: "long", year: "numeric"})
> }
>
> function __replace(arg) {
> return function(string, group) {
> return '<span class="' + arg + '">' + group + '</span>'
> }
> }
>
> function replaceTextFormatting(string) {
> var regex = /\\texttt{(.*?)}/
> string = string.replace(regex, __replace('texttt'))
>
> regex = /\\textit{(.*?)}/
> string = string.replace(regex, __replace('textit'))
>
> regex = /%.*$/g
> string = string.replace(regex, '')
>
> regex = /\\hyp{}/g
> string = string.replace(regex, '-')
>
> return string
> }
>
> function fixupWorkRole(role) {
> role["start-date"] = fixupDate(role["start-date"])
> role["end-date"] = fixupDate(role["end-date"])
>
> role.responsibilities.forEach(
> r => r.details.forEach(
> d => d.detail = replaceTextFormatting(d.detail)
> )
> )
>
> return role
> }
>
> function fixupResearchRole(role) {
> role["start-date"] = fixupDate(role["start-date"])
> role["end-date"] = fixupDate(role["end-date"])
>
>
> role.details.forEach(
> d => d.detail = replaceTextFormatting(d.detail)
> )
>
> return role
> }
>
> function _workRoles(results) {
> var array = results[0].values.map(
> v => fixupWorkRole(JSON.parse(v))
> )
>
> return { "companies": array }
> }
>
> function _researchRoles(results) {
> var array = results[1].values.map(
> v => fixupResearchRole(JSON.parse(v))
> )
>
> return { "research": array }
> }
>
30,31c86
< function execute(commands) {
< tic();
---
> function execute() {
34d88
< toc("Executing SQL");
40,49c94,95
< tic();
< outputElm.innerHTML = "";
< for (var i = 0; i < results.length; i++) {
< outputElm.appendChild(tableCreate(results[i].columns, results[i].values));
< }
< toc("Displaying results");
< }
< worker.postMessage({ action: 'exec', sql: commands });
< outputElm.textContent = "Fetching results...";
< }
---
> var workRoles = _workRoles(results)
> var researchRoles = _researchRoles(results)
51,66c97,98
< // Create an HTML table
< var tableCreate = function () {
< function valconcat(vals, tagName) {
< if (vals.length === 0) return '';
< var open = '<' + tagName + '>', close = '</' + tagName + '>';
< return open + vals.join(close + open) + close;
< }
< return function (columns, values) {
< var tbl = document.createElement('table');
< var html = '<thead>' + valconcat(columns, 'th') + '</thead>';
< var rows = values.map(function (v) { return valconcat(v, 'td'); });
< html += '<tbody>' + valconcat(rows, 'tr') + '</tbody>';
< tbl.innerHTML = html;
< return tbl;
< }
< }();
---
> console.log(workRoles)
> console.log(researchRoles)
68,95c100,104
< // Execute the commands when the button is clicked
< function execEditorContents() {
< noerror()
< execute(editor.getValue() + ';');
< }
< execBtn.addEventListener("click", execEditorContents, true);
<
< // Performance measurement functions
< var tictime;
< if (!window.performance || !performance.now) { window.performance = { now: Date.now } }
< function tic() { tictime = performance.now() }
< function toc(msg) {
< var dt = performance.now() - tictime;
< console.log((msg || 'toc') + ": " + dt + "ms");
< }
<
< // Add syntax highlihjting to the textarea
< var editor = CodeMirror.fromTextArea(commandsElm, {
< mode: 'text/x-mysql',
< viewportMargin: Infinity,
< indentWithTabs: true,
< smartIndent: true,
< lineNumbers: true,
< matchBrackets: true,
< autofocus: true,
< extraKeys: {
< "Ctrl-Enter": execEditorContents,
< "Ctrl-S": savedb,
---
> outputElm.innerHTML =
> "<h2>Work Experience</h2>"
> + Mustache.render(workRoleTemplate, workRoles)
> + "<h2>Research Experience</h2>"
> + Mustache.render(researchRoleTemplate, researchRoles)
97d105
< });
99,118c107,108
< // Load a db from a file
< dbFileElm.onchange = function () {
< var f = dbFileElm.files[0];
< var r = new FileReader();
< r.onload = function () {
< worker.onmessage = function () {
< toc("Loading database from file");
< // Show the schema of the loaded database
< editor.setValue("SELECT `name`, `sql`\n FROM `sqlite_master`\n WHERE type='table';");
< execEditorContents();
< };
< tic();
< try {
< worker.postMessage({ action: 'open', buffer: r.result }, [r.result]);
< }
< catch (exception) {
< worker.postMessage({ action: 'open', buffer: r.result });
< }
< }
< r.readAsArrayBuffer(f);
---
> worker.postMessage({ action: 'exec', sql: queries });
> outputElm.textContent = "Fetching results...";
121,141c111,134
< // Save the db to a file
< function savedb() {
< worker.onmessage = function (event) {
< toc("Exporting the database");
< var arraybuff = event.data.buffer;
< var blob = new Blob([arraybuff]);
< var a = document.createElement("a");
< document.body.appendChild(a);
< a.href = window.URL.createObjectURL(blob);
< a.download = "sql.db";
< a.onclick = function () {
< setTimeout(function () {
< window.URL.revokeObjectURL(a.href);
< }, 1500);
< };
< a.click();
< };
< tic();
< worker.postMessage({ action: 'export' });
< }
< savedbElm.addEventListener("click", savedb, true);
---
> var worker = new Worker("../../dist/worker.sql-wasm.js");
> worker.onerror = error;
>
> function loadDatabase(event) {
> var arrayBuffer = this.response
>
> worker.onmessage = function(event) {
> console.log("Done loading database")
> execute()
> };
>
> try {
> worker.postMessage({ action: 'open', buffer: arrayBuffer }, [arrayBuffer]);
> }
> catch (exception) {
> worker.postMessage({ action: 'open', buffer: arrayBuffer });
> }
> }
>
> var request = new XMLHttpRequest()
> request.onload = loadDatabase
> request.open("GET", "/db/db.sqlite3")
> request.responseType = "arraybuffer"
> request.send()